Hangisini seçmeliyim?
Bir makine öğrenmesi / veri madenciliği çalışmasında problemin alan tayini çok önemlidir. Bu yazımda supervised (gözetimli – eğitimli) ve unsupervised (gözetimsiz – eğitimsiz) öğrenme konuları hakkında bilgi vermeye çalışacağım. Bu bilgiyi verirken “Yazar Tanıma” ve “Sınıf içinde kopya çeken öğrenciyi bulma” problemleri üzerinde üretilebilecek çözümlerle konuyu pekiştirmeye çalışacağım.
Gözetimli Öğrenme
Eğitim verileri üzerinden bir fonksiyon üreten bir makine öğrenmesi tekniğidir. Başka bir deyişle, bu öğrenme tekniğinde girdilerle (işaretlenmiş veri – labelled data) ile istenen çıktılar arasında eşleme yapan bir fonksiyon üretir. Eğitim verisi hem girdilerden hem çıktılardan oluşur. Fonksiyon, sınıflandırma (classifiction) veya eğri uydurma (regression) algoritmaları ile belirlenebilir.
| Yandaki örnekte örnek bir veri için bir f(x) fonksiyonu belirlenmiştir. Bu f(x) fonksiyonunun %100 her şeyi tahmin etmesini beklemeyin. Dikkat ettiyseniz bazı kırmızılar maviler arasında bazı mavilerde kırmızılar arasında kalmıştır. Ama genel duruma bakıldığında çoğu durum için kullanılabilecek bir fonksiyon olduğunu görüyoruz. Bu f(x) fonksiyonu yeni gelen veriler için kullanılabilir. | 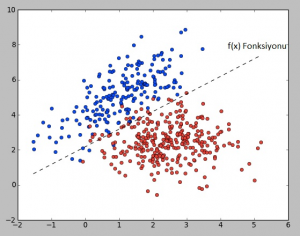 |
Gözetimsiz Öğrenme
Bu yöntemde işaretlenmemiş (unlabelled) veri üzerinden bilinmeyen bir yapıyı tahmin etmek için bir fonksiyon kullanan makine öğrenmesi tekniğidir. Burada girdi verisinin hangi sınıfa ait olduğu belirsizdir.
| Yandaki örnekte başlangıçta küme sayısının bilinmediği görülmektedir. Algoritma yine bir f(x) fonksiyonu ile kümelere karar verir. Bu f(x) genel bir matematiksel formüldür, eğitim verisinden hesaplanmaz. Örneğin yeni bir nokta geldiğinde bu üç küme ile uzaklıklarına bakılır ve ya yeni bir küme oluşturuluyor ya da mevcut kümelerden birine dahil olur. (Algoritma türüne göre çalışması değişir.) | 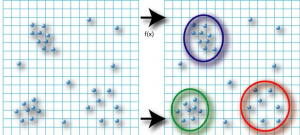 |
Gözetimli Öğrenme vs. Gözetimsiz Öğrenme
Gözetimli öğrenmenin en kötü tarafı eğitim verisi oluşturmaktır. Eğitim verisi sayesinde bir makine öğrenmesi metodu ile (yüzlerce metot var) bir fonksiyon üretilir. Bu fonksiyon ile yeni gelen veriler tahmin edilmeye çalışır. Gözetimli öğrenmesinin en zaman alıcı kısmı bu eğitim verisinin hazırlanması kısmıdır. Kötü hazırlanmış bir eğitim verisinin çok kötü tahminler yapacağını unutmayın. Eğitim verisi hazırlarken 2-3 kişinin gözetiminden geçmesinde yarar vardır.
Gözetimsiz öğrenmede ise bir eğitim verisi yoktur. Grupları algoritma (unsupervised öğrenme içinde onlarca algoritma vardır) öğrenmeye çalışır. Bu bölümdeki algoritmalar verileri gruplanarak yeni veriyi en uygun gruba atamaya çalışır. Eğitim verisi olmadığı için uygulaması kolaydır. Ancak, zor problemlerde pek iyi sonuçlara ulaşamayabilirsiniz. Peki ben ne zaman gözetimli ne zaman gözetimsiz öğrenme kullanacağım.
Bir gözetimli öğrenme problemi: Yazar tanıma
Daha önceki yazımda farkı bir alandaki problemi çözmek için gözetimli öğrenme kullanılmıştır. Fakat bu gün farklı bir alandaki probleme çözüm bulmaya çalışalım. Bu günkü problem, Dr. Pınar Tüfekci arkadaşımla yaptığım yazar tanıma çalışması üzerine olacaktır. Elimizde 10 tane yazar ve 400 tane makale olsun. Eğer, yeni gelen bir makalenin kime ait olduğunu bilmiyorsan ve tahmin etmek istiyorsam: geçmiş bilgileri kullanmakta yarar vardır. İşte geçmiş bilgilerin önem kazandığı çalışmalarda gözetimli öğrenme kullanılır. (Gözetimli öğrenme üzerine daha önceki çalışmalarım: Web içerik çıkarımı (benim çalışma alanım:)), yorum etiketlerinden olumlu/olumsuz yorum çıkarımı(proje öğrencilerimle yapmıştım))
Bir gözetimli öğrenme problemi çözmek için aşağıdaki adımlar takip edilir:
- Eğitim setini oluşturma: Çalışacağımız alana dair bilgiler toplamalıyız. Yazar tanıma için yazar ve makalelerden oluşan bir veri bulmakla başlayabiliriz. İnternetten farklı yazarlar bulup ve makalelerini toplayıp metin formatında dosyalarımıza kopyalayıp yapıştırabiliriz. (Eğitim setinin büyüklüğü size kalmış, iyi tahmin için büyük olması önemli. Ayrıca yazara ait bir değil, birden fazla makale içermesi önemli. Örneğin A yazarında 100 makale ve B yazarında 1 makale yaparsak overfitting dediğimiz konu oluşur. Tahmin mekanizması (fonksiyonu) B yazarı hiç bir zaman tahmin edemez. )
- Eğitim setinin girdi alanları ve çıktı alanına karar verme: Eğitim verisi içindeki girdi alanları ve sonuçta üretilecek sonucu uygun formatta hazırlamalıyız. (Eğer kodu tamamen biz yazacaksak programla dilinde bir List, bir dizi. Eğer farklı sınıflama tekniklerini test etmek istiyorsak uygun metin formatında verimizi hazırlamakta yarar vardır. Örneğin Weka için ARFF dosya yapısı olabilir. (Excel bile olabilir). Benim tavsiyem Weka gibi yardımcı bir araç ile uygun algoritma tayini yapıp o algoritma üzerine yönlenmeniz olacaktır.) Eğitim verisini hazırlarken girdiler büyük önem taşır. Örneğin, yazar tanıma da yazarın ortalama cümle uzunluğu, hangi kelimeye ne kadar kullandığı, kullandığı bağlaç sayısı, çok kullandığı bağlaçlar ve sayıları, passive (edilgen) cümle sayısı ve vb. alanlara ait bilgiler kullanılabilir. (Aman bu bilgileri el ile girmeyin, kelime analizi yapan bir program yazın. Türkçe için zemberekten birçok özellik üretebilirsiniz.) Bu bilgileri sayısal değer kullanma yerine tüm makale içindeki orantısını da kullanabiliriz. (Bu olaya normalizasyon deniyor. Örneğin Beşiktaş kelimesi A dökümanında 100 kelime arasında 5 tane B dokümanında ise 40 kelime arasında 5 tane olduğunu farz edin. Bu durumda 5/100 ve 5/40 bir veri olarak kullanılabilir.) Eğitim setimizi hazırlarken yazar isimlerini unutmayalım.
- Öğrenme algoritmasının seçimi: Weka gibi bir araç ile aynı eğitim setini farklı algoritmalarla test edip doğruluk açısından en uygun algoritmaya karar vermeliyiz. (Doğruluk ve karşılaştırma için ayrı bir blog yazısı yazacağım.)
- Algoritma tayini ve çalışan sistem: Eğitim seti dışında bir makaleyi sisteme verdiğimizde sistemimiz tahminde bulunur. Ayrıca bir test verisi ile tahminlerin başarısını ölçmede sisteminizi değerlendirmekte yarar vardır.