Normalizasyon, ilişkisel modelin bulucusu Edgar F. Codd (1970) tarafından tanıtılmıştır. Her ne kadar veritabanı tasarımında kullanılan önemli bir işlem olmasına rağmen ne zaman durulacağı, ne zaman alt tablolara gidileceği ve ne zaman normalizasyon yapılmayacağı uygulama analizi ile alakalıdır. Bu blog yazımda, örnek bir senaryo üzerinden uygulamadaki değişikliklere göre farklı normalizasyon durumlarını incelemeye çalışacağım. Tasarım işlemine destek ve normalizasyonun uzun işlemlerini aşmak için Varlık-İlişki modelini anlatıp, tasarım olayına performans açısından da bakacağız.
Normalizayon
Normalizasyon tanım olarak, veri tabanı tasarım aşamasında veri tekrarını, veri kaybını veya veri yetersizliğini önlemek için gerçekleştirilen işlemlerdir. (Prof.Dr. Oya Kalıpsız, Bilgisayar Veri Tabanı Sistemleri) Başka bir deyişle, veritabanlarında çok fazla sütun ve satırdan oluşan bir tabloyu tekrarlardan arındırmak için daha az satır ve sütun içeren alt kümelerine ayrıştırma işlemidir. (http://tr.wikipedia.org/wiki/Normalizasyon)
Bir kitap otomasyonu yaparken aşağıdaki verileri görüştüğümüz yerden topladığımızı farz edelim.

Kitaplar(KitapNo, KitapAdı, Yazarı, YayınEviAdı, YayınEviYeri, TürID, TürAdı)
1. NF’u hatırlayarak başlayalım. Birinci Normal Form, “Atomik İlişkilerin Çözümlenmesi”, için veriye ihtiyaç duyarız. Örneğin Yazarı bilgisi “Memik Yanık” ad soyad bilgisini ayırmamız gerekir. Ama her zaman ayırmak gerekli mi bunu son kısımda inceleyeceğiz.
2. NF, “kısmi işlevsel bağımlılıkların çözümlenmesi”, için KitapNo alanı tek başına birincil anahtar olabildiği için bu bağımlılığa gerek duymayız.
3. NF, “geçişli işlevsel bağımlılıkların çözümlenmesi”, için Kitap Bilgisi üzerindeki YayınEviAdı ve TürID bilgileri ayrı tablolara ayrılabilir. Bu durumda:
3.NF:
Kitaplar(KitapNo, KitapAdı, YazarAdı, YazarSoyadı, YayınEviAdı, YayınEviYeri, TürID, TürAdı)
Bağımlılıklar: TürID->TürAdı, YayınEviAdı->YayınEviYeri
Kitaplar(KitapNo, KitapAdı, YazarAdı, YazarSoyadı, YayıneviAdı, TürID)
Türler(TürID, TürAdı)
YayınEvleri(YayınEviAdı, YayıneviYeri)
Normalizasyon kuralları ile buraya kadar gelebiliriz. Ancak, iyi bir veritabanı tasarımcısı veri’deki yetersizlikleri de tespit edip önlemler alabilmelidir. Bu yetersizlikler veri kayıplarına da sebebiyet verebilir. Yukarıdaki örnekte her ne kadar YayınEviAdı birincil anahtar gibi kullanılsa da birincil anahtarın kısa ve daha rahat kontrol edilebilir bir veri olması gerekmektedir. Bu tür bir veri içinde birincil anahtar oluşturmak zor bir süreçtir. T.C. Kimlik No, Sicil No ve FaturaNo gibi değerler belli bir kurala göre üretilebilir ancak bazı durumlarda bu kuralı bulmak zor olabilir. Böyle bir durumda tüm VTYS için genel bir çözüm artan sayı kullanmaktır. YayınEviID adında yeni bir özellik üretebiliriz. Ayrıca, Yazar içinde YazarID üretilebilir.
Kitaplar(KitapNo, KitapAdı, YazarAdı, YazarSoyadı, YayınEviID, TürID)
Türler(TürID, TürAdı)
YayınEvleri(YayınEviID, YayıneviAdı, YayıneviYeri)
Yazarlar(YazarID, YazarAdı, YazarSoyadı)
KitapNo, TürID, YayınEviID, YazarID gibi bilgiler otomatik artan sayı yapılabilir. Uygulama tarafında otomatik artan sayı kullanıcılara gösterilmeyebilir ama silme ve düzeltme gibi işlemler bu sayı üzerinden yapılmalıdır. Bu kısımda, veritabanı tasarımı yapılan sistemin mevcut çalışması da iyi bir şekilde incelenmelidir. Örneğin, çalışan sistemde KitapNo için özel bir format var ise bu formata başvurulabilir. Diğer bir taraftan, “bir kitabın birden fazla yazarı olabilir mi?“, “bir kitabın birden fazla yayınevi olabilir mi?” ve “bir kitabın birden fazla türü olabilir mi?” gibi sorulara kullanıcılardan alınacak cevaplarda tasarımı büyük ölçü de değiştirir. Bu gibi noktalarda, uygulama analiz safhasında yapılacak görüşmeler büyük önem kazanmaktadır. Örneğin, yukarıdaki sorulara şu cevapları aldığımızı farz edelim: “kitabın bir yazarı var“, “sadece bir yayınevi var“, “bir kitabın tek türü var“. Bu durumda her şeye sil baştan başlamak gerek: KitapNo, YazarID, TürID yapılan tanım ile 2.NF’ların çözümlenmesi durumuna gelmiştir. Başka bir deyişle kısmi işlevsel bağımlılık olmuştur. YayınEviID, bir kitabın tek yayınevi olması dolayısıyla 3. NF ile çözümlenir.
Kitaplar(KitapNo, KitapAdı, YazarID, YazarAdı, YazarSoyadı, YayınEviID, YayınEviAdı, YayınEviYeri, TürID, TürAdı)
2. NF:
Kitaplar(KitapNo, KitapAdı, YayınEviID, YayınEviAdı, YayınEviYeri, YazarID, TürID)
Yazarlar(YazarID, YazarAdı, YazarSoyadı)
Türler(TürID, TürAdı)
3. NF:
Kitaplar(KitapNo, KitapAdı, YazarID, TurID, YayınEviID)
YayınEvleri(YayınEviID, YayınEviAdı, YayınEviYeri)
E-R (Entity Relationship / Varlık İlişki) Modellemesi
Uygulama geliştirme sırasında analiz en önemli safhalardan birisidir. Bu kısımda kullanıcı/müşteriye sorulacak sorular tüm sistemin tasarımını değiştirir. Fakat, yüzlerce verinin olduğu sistemlerde tasarım sırasında normalizasyon kurallarına göre değişiklik yapmak çok zahmetli bir süreçtir. Bunun yerine 1976 yılında Peter Chen tarafından önerilen varlık-İlişki modeli işlemlerimizi kolaylaştırabilir. Varlık-İlişki modeli kullandıktan sonra normalizasyon işlemine devam etme veritabanı tasarımında sıklıkla kullanılan tekniklerden biridir.
Normalizasyon ilişkisel veritabanı tasarımda karşılaşılan belirli sorunlarından kaçınmak ve analize yardımcı olmak için kullanılan mantıksal kurallar kümesidir. ER ise veri modeli yapmak için analiz teknikler kümesidir. Her ikisi de ilişkisel veritabanı tasarımda sıklıkla kullanılır. Kaba bir tabirle, ER varlıkları ve ilişkilerini dikkate alan yukarıdan-aşağı (top-down) bir yaklaşım iken normalizasyon özellikler arasındaki bağımlılıkları dikkate alan aşağıdan-yukarı (bottom-top) bir yaklaşımdır.
ER modelleme her ne kadar derslerde gösterilse de veritabanı ilişkisel şemalar ve UML gibi alternatifler geliştirme tarafında kullanılır. ER ise veritabanında profesyonel olmayan kullanıcılarla iletişimde ve veritabanı dersi eğitimde ilk defa bu konu ile karşı karşıya kalmış öğrencilerin eğitimde sıklıkla kullanılır. Yukarıdaki örneğin son halinin ER diyagramı aşağıdaki gibidir.
Yukarıdaki örnekte öncelikle sınıflar ve sınıflar arasındaki ilişkiler verilmiştir. Varlıklar ile bağlantı kısmdanda tek çizgili taraflar 1 ve çok çizgili taraflar N anlamına gelmektedir. Varlık ilişki üzerinden ilişkiler değiştirilebilir.
Yukarıdaki örnekte, analiz aşamasında şu sorulara şu cevapları verdiğimiz için tasarım böyle olur. Bu sorular neydi?
- bir kitabın birden fazla yazarı olabilir mi? – kitabın bir yazarı var
- bir kitabın birden fazla yayınevi olabilir mi? – sadece bir yayınevi var
- bir kitabın birden fazla türü olabilir mi? – bir kitabın tek türü var
Peki bu sorulara eğer şöyle cevap verseydik.
- bir kitabın birden fazla yazarı olabilir mi? – kitabın birden fazla yazarı var
- bir kitabın birden fazla yayınevi olabilir mi? – sadece bir yayınevi var
- bir kitabın birden fazla türü olabilir mi? – bir kitabın birden fazla türü var
Bu durumda ER tasarımı:
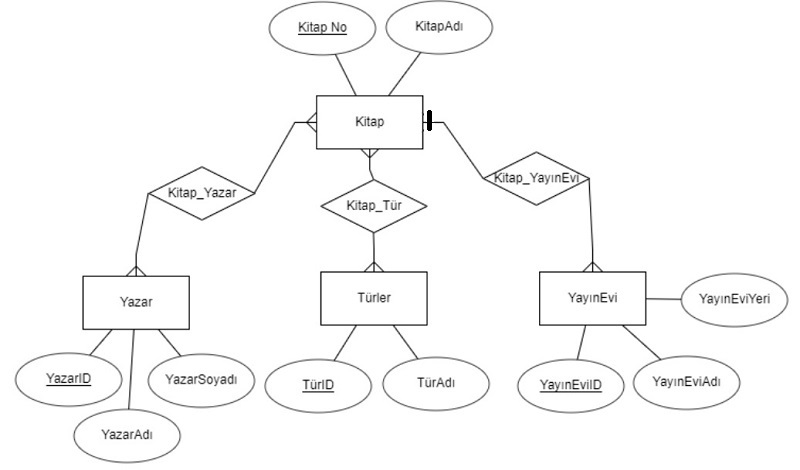
Bu durumda tasarım:
Kitaplar(KitapNo, KitapAdı, YayınEviID)
Yazarlar(YazarID, YazarAdı, YazarSoyadı)
Türler(TürID, TürAdı)
Kitap_Yazar(KitapNo, Yazar_D)
Kitap_Tür(KitapNo, TürID)
YayınEvleri(YayınEviID, YayınEviAdı, YayınEviYeri)
Tasarım sorulara göre nasıl değiştiğini gördük. Şimdi bir soru ile devam edelim.
Şimdi bir soru: Yukarıdaki ER modelinde tekrarlayan veri var mı?
Cevap:
YayınEvi bölümünde YayınEviYeri özelliği tekrar eder. Normalizasyon bir amacı tekrarlayan verileri bulup ayrı tabloya ayırmaktır. YayınEviYeri -> ŞehirID, ŞehirAdı olarak iki özelliğe ayrılıp yeni bir varlık oluşturulabilir. YayınEvi ile YayınEviYeri arasında 1-N ilişki oluşturulur. Fakat, uygulama tarafında YayınEviYeri için bir form/sayfa tasarlayıp tüm şehir bilgilerinin girilmesi ve sonra YayınEvi kayıt işlemi yapılırken ŞehirAdı’nın seçilmesi gerekir. ŞehirAdı verisi çok fazla olduğunda, seçim işlemi ve arama işlemi uygulamanın kullanımı zorlaştırabilir. Bu durumda, bu normalizasyonun yapılıp yapılmasına uygulama tarafında kullanıcının rahat kullanımı göz önüne alınarak karar verilebilir. Sadece, kullanıcı rahat kullanımı değil aynı zamanda performans içinde normalizasyon işlemini yapmamak gerekebilir.
UYGULAMA TARAFI: PERFORMANS
Buraya kadar veritabanı tasarımında dikkat edilecek noktaları anlattık. Uygulama tarafında kullanıcının rahat kullanımı göz önüne alıp normalizasyon işlemi yapılmayabileceğini belirttik. Diğer taraftan, veritabanı konusunda profesyonel çalışan kişiler performans kriterini de göz önüne alarak normalizasyon işleminden vazgeçebilir. Hatta literatürde, performans arttırmak ve sorgu sürelerini azaltmak için denormalizasyon işlemi önerilir.
Bir örnek üzerinden normalizasyon’dan vazgeçmenin yararını anlatalım. En temel normalizasyon işlemini, 1 NF, yapmayarak başlayalım. 1 NF’da, Yazarı özellliğini YazarAdı ve YazarSoyadı olmak üzere iki özelliğe bölmüştük. Ancak, YazarAdı ve YazarSoyadı özelliklerinin her biri üzerine sıralama ve arama işlemi yapmayacaksak Yazarı özelliğini kullanmak performansımızı arttıracaktır. Bir sorgu işlemi ile YazarAdı ve YazarSoyadını çektiğimizde iki karakter dizisini çektiğimizde, yani YazarAdı + ” ” + YazarSoyadı, bu karakter dizilerini birleştirmek CPU tarafında zaman kaybıdır. Milyonlarca kişinin ziyaret ettiği bir internet sitesi yaptığımızda Yazarı özelliğini direkt kullanmak büyük zaman kazancı olur.
Diğer bir performans arttırma yöntemi (denormalizasyon) tablo sayısını düşürmektir. 5 tablo üzerinden veri çekmek (Join’ler ileride anlatılacak) yerine 3 tablo üzerinden veri çekmenin yine performans kazancı sağlayacağını unutmamalıyız. Performans artışı için uygulama tarafını iyi etüt etmekle birlikte güncel konuları bilmenin ve veritabanı tasarımdaki tecrübenin önemi çok büyüktür. Normalizasyon işlemine karşı yapılan demormalizasyon işlemi ilişkisel model üzerinde yapılır. 1970’lerde önerilen ilişkisel model yerine 2000 yıllarda ilişkisel modele de karşı çıkan NoSQL’ciler çıkmıştır. Sorgu optimizasyonu, denormalizasyon ve NoSQL üzerine derslerde bilgi vereceğiz ve ayrıca bu konularda blog yazıları düşünüyorum. Yazım sonunda iyice aklınız karıştı. Bilgisayar Bilimi ne yazık ki çok değişken bir alandır. Kurallar zamanla esneyebilir, değişebilir ve hatta tamamen kaybolabilir. Bu alanda yaşayabilmek için uygulama geliştirmeyi sevmeniz ve çok çalışmanız gerektiğini unutmayın arkadaşlar. Mark, Facebook’u 2004 yılında geliştirilmeye başladığında sadece veri tutmak için ilişkisel modeli destekleyen MySQL’i kullanıyordu. Şimdi ise veri tutma da hem ilişkisel hemde ilişkisel olmayan (NoSQL) ortamları kullanıyor.
İyi çalışmalar arkadaşlar…
TEŞEKKÜRLER
REFERANSLAR
