Karar ağaçları – sınıflama, özellik ve hedefe göre karar düğümleri (decision nodes) ve yaprak düğümlerinden (leaf nodes) oluşan ağaç yapısı formunda bir model oluşturan bir sınıflandırma yöntemidir. Karar ağacı algoritması, veri setini küçük ve hatta daha küçük parçalara bölerek geliştirilir. Bir karar düğümü bir veya birden fazla dallanma içerebilir. İlk düğüme kök düğüm (root node) denir. Bir karar ağacı hem kategorik hem de sayısal verilerden oluşabilir.
ZeroR konusundaki verimiz üzerinden konuyu anlatmaya çalışacağım. Öncelikle bir karar ağacını görelim. Daha sonrasında adım adım bu karar ağacı nasıl oluşturacağımızı anlatalım. Aşağıda verilerimizi ve bu verilerden elde edilmiş karara ağacı gösterilmektedir.

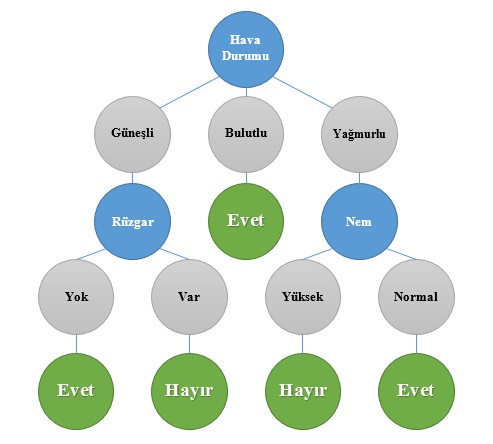
Karar ağacını IF-ELSE IF-ELSE statements kullanarak rahatlıkla her hangi bir programlama dilinde kodlaya bilirsiniz. Örneğin Hava Durumu üç IF şart içerir. 2. IF şartı “Bulutlu” seçilmişse “Futbol Oyna” için olumlu sonuç döndürülür.
ID3 Algoritması
J.R. Quinlan, tarafından 1986 yılında bir veri setinden “karar ağacı” üretmek için geliştirilen ID3 algoritması geliştirmiştir. Bu algoritma aşağıdan yukarı (top-down : kökten alt dallara doğru) ve greedy search (sonuca en yakın durum) teknikleri kullanılır. Decision Tree konusunda sıklıkla göreceğiz C4.5 algoritması ID3 algoritmasının bir uzantısıdır. ID3 algoritması Entropy ve Information Gain üzerine inşa edilmiştir.
Entropy: rastgeleliğe, belirsizliği ve beklenmeyen durumun ortaya çıkma olasılığını gösterir. Eğer örnekler tamamı düzenli / homojen ise entropisi sıfır olur. Eğer değerler birbirine eşit ise entropi 1 olur. Örneğin Futbol Oyna hepsi “Evet” veya “Hayır” olsa entropi sıfır olurdu. Entropi formülasyonu:







Information Gain (Bilgi Kazanımı)
Bilgi kazanımı, bir veri setini bir özellik üzerinde böldükten (Örneğin E(FutbolOyna, HavaDurumu)) sonra tüm entropiden (E(FutbolOyna)) çıkarmaya dayanır. Entropinin küçük değer içermesi durumunda özelliğin önemi Decision Tree algoritması ID3 için artmaktadır. Diğer taraftan 1’e yaklaştıkça özelliğinin önemi azalır. Ancak information gain’de olay tam tersidir ve bu açıdan entropinin tersi gibi düşünülebilir. Decision Tree inşa edilirken en yüksek değerleri information gain’e sahip özellik seçilir.
![]()
Gain(FutbolOyna, HavaDurumu) = E(FutbolOyna) – E(FutbolOyna, HavaDurumu)
Gain(FutbolOyna, HavaDurumu) = 0.940 – 0.694 = 0.247 *
Gain(FutbolOyna, Nem) = 0.940 – 0.788 = 0.152
Gain(FutbolOyna, Sıcaklık) = 0.940 – 0.911 = 0.029
Gain(FutbolOyna, HavaDurumu) = 0.940 – 0.892 = 0.048
Gain(FutbolOyna, HavaDurumu) özelliği en yüksek information gain değerine sahiptir. Bu özellik seçildikten sonra özelliğin değerlerine bakılarak en yüksek information gain’e sahip alan seçilir. HavaDurumu Bulutlu olduğunda tüm FutbolOyna değerleri Evet’tir. Şekil olarak aşağıdaki gibidir:


Hava Bulutlu ise Futbol oynuyoruz:) İkinci aşamada HavaDurumu Güneşli olan durumlar seçilir. Güneşli olduğunda oynama ve oynama durumları vardır. Bu durumda tekrar information Gain hesaplanır ve Rüzgar durumunun karar verici bir özellik olduğu görülür.


Rüzgar var ise oynayamıyoruz 🙁 Rüzgar yok ise oynayabiliyoruz 🙂 Özyinelemeli bir şekilde yaprak kalmayıncaya kadar ID3 algoritması devam eder.
Overfitting(Aşırı Uyum)
Overfitting karar ağacı modelleri ve diğer pek çok tahmin modeli için önemli bir sorundur. Öğrenme algoritması etkileyecek şekilde eğitim seti hatalarını azaltmaya devam edildiğinde overfitting olur. Bir karar ağaç inşasında overfitting’ten kaçınmak için genelde iki yaklaşım kullanılır.
- Pre-pruning: Sınırlandırma işleminde önce ağacın büyümesini durdurmak.
- Post-pruning: öncelikle tüm ağacı oluşturup daha sonra ağaçtaki gereksiz kısımları çıkarmak.
- Budama işlemine karar vermek için eğitim verisinden farklı bir veri seti kullanmak. Bu veri setine doğrulama veri seti (validation dataset) denir. Validation dataset gereksiz düğümlere karar vermek için kullanılır.
- Bir karar ağacı elde ettikten sonra, hata tahmini (error estimation) ve önem testi (Significance testing – Chi Square Testing) gibi istatiksel metotlar kullanarak eğitim verisi üzerinde budama ve genişleme (expanding – ağaça yeni node’lar ekleme) olup olmayacağına karar verilir.
- Minimum Description Length principle: karar ağacı ile eğitim veri seti arasında bir ölçüdür. Boyut(tree) + Boyut(sınıflanamayan(tree)) minimize olduğunda ağaç büyümesini durdurma.
Referans